Keyword [Hashtags] [Social Media Images]
Mahajan D, Girshick R, Ramanathan V, et al. Exploring the limits of weakly supervised pretraining[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 181-196.
1. Overview
1.1. Motivation
- the large pre-training datasets are difficult to collect and annotate
In this paper
- present a study transfer training with large network trained to predict hashtags on billions of social media images (Weak Supervised)
- training for large-scale hashtag prediction leads to excellent result
1.2. Hashtags Dataset
- billions of images “labeled” in the wild with social media hashtags (no manual labeling)
- hashtags are noisy and image distribution might be biased
multi-label samples. if has k hashtags, then each hashtag is 1/k probability
pre-processing
- utilize WordNet synsets to merge some hashtags into a single canonical form
- deduplication between training and test sets. compute R-MAC features use kNN (21)

1.3. Model
- ResNeXt-101 32xCd (classification). 32 groups, C group width
- Mask R-CNN (detection).
- Cross-Entropy. sigmoid and binary logistics get worse results
1.4. Training Methods
- Full Network Finetuning. view pre-training as sophisticated weight initialization
- Feature Transfer. pre-trained network as feature extractor, without updated, only trained classifier
Ensure the experiments of paper on the standard validation sets are clean.
1.5. Dataset
- ImageNet
- CUB2011
- Places365
1.6. Related Work
- JFT-300M. 300 million weakly supervised images, proprietary and not publicly visible
- Word or n-gram supervision. weaker than hashtag supervision
1.7. Observation
- maybe important to select a label space for the source task to match the target task
- current network are underfitting when trained on billions of images. lead to very high robustness to noise in hashtags
- training for large-scale hashtag prediction improves classification while at the same time possibly harming localization performance
2. Experiments
2.1. Hashtags Vocabulary Size

- pre-trained with 17k hashtags strongly outperforms 1.5k hashtags
- 17k span more objects scenes and fine-grained categories
2.2. Training Set Size
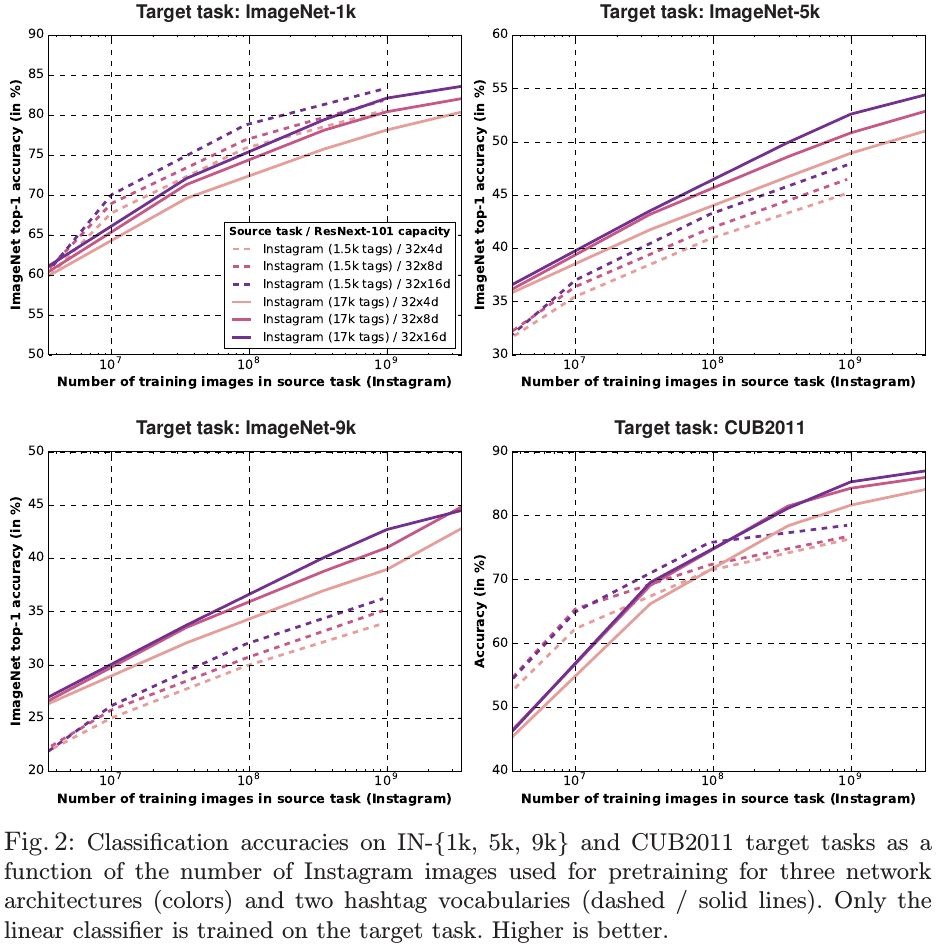
- when training network on billions of training images, current network architecture are prone to underfitting
- on IN-1k, pre-trained with 1.5k hashtags outperform other larger hashtags
- as the matching between hashtags and target classes disappear, larger hashtags outperform
- the effectiveness of the feature representation learned from hashtag prediction.
train linear classifier on fixed feature are nearly as good as full network finetuning. - For CUB2011. when training data is limited, the 1.5k hashtag dataset is better
2.3. The Noise of Hashtags
Randomly replaced p% of the hashtags by hashtags obtained by sampling from the marginal distribution over hashtags.

2.4. The Sampling Strategy of Hashtags

- using uniform or square-root sampling lead to an accuracy improvement
2.5. Model Capacity

- with large-scale Instagram hashtag training, transfer-learning performance appears bottlenecked by model capacity
2.6. Most Helpful Class of Pre-training

- more concrete, more helpful
2.7. Detection

- when using larger pre-training data, detection is model capacity bound
- gains from Instagram pre-training mainly due to improved object classification rather than spatial localization